高标准的实验室是进行基因检测和数据分析的前提和基础。基因宝在创立之初就自建了符合国家临检标准的医学检验实验室。目前实验室已通过二级生物安全实验室、临床基因扩增检验实验室的技术合格验收,并多次满分通过国家卫生健康委临检中心室间质评,确保检测结果的准确和可靠。
实验流程白皮书旨在通过实验流程和详细的质量控制介绍,帮助用户理解唾液是如何一步一步变成 App 上可见的检测报告,并接受用户和专业人士的监督。
实验室的收样人员确认收件后,会以短信的形式通知,同时也会在基因宝 App 中更新信息。若在物流过程中有任何问题均可以与基因宝的客服进行沟通,客服电话为:17801274980。
实验室工作人员在对唾液样本进行预处理后,就会进入实验环节,在实验环节中工作人员会严格遵守如下图所示法规及准则,以便为用户提供准确、可靠的医学检测服务。
医学检验实验室法规及准则
| 法规及准则 | 发布时间 | 监管部门 |
| CNAS-CL02:2012医学实验室质量和能力认可准则 | 2012 | 中国合格评定国家认可委员会 |
| CNAS-CL02-A010:2018《医学实验室质量和能力认可准则在实验室信息系统的应用说明》 | 2018 | 中国合格评定国家认可委员会 |
| CNAS-CL02-A009:2018《医学实验室质量和能力认可准则在分子诊断领域的应用说明》 | 2018 | 中国合格评定国家认可委员会 |
| 微生物和生物医学实验室生物安全通用准则 | 2003.08.01 | 国家卫生和计划生育委员会、国家标准化管理委员会 |
| 《实验室生物安全手册》(第3版) | 2007.08.01 | 世界卫生组织 |
| 实验室危险化学品安全管理规范 | 2018.10.01 | 北京市质量技术监督局 |
| 常用危险化学品储存通则 | 1996.02.01 | 国家技术监督局 |
| 国家危险废物名录 | 2016.08.01 | 环境保护部(已撤销),国家发展和改革委员会(含原国家发展计划委员会、原国家计划委员会),公安部 |
| 医疗卫生机构医疗废物管理办法 | 2003.10.15 | 中华人民共和国卫生部 |
| 医疗废物集中处置技术规范 | 2003.12.26 | 中华人民共和国环境保护部 |
| 实验室生物安全通用要求 | / | 全国认证认可标准化技术委员会 |
| 中华人民共和国卫生部令(第45号)可感染人类的高致病性病原微生物菌(毒)种或样本运输管理规定_2006年第33号国务院公报 | 2006.02.02 | 中华人民共和国卫生部 |
| 国家卫生健康委办公厅关于印发新型冠状病毒肺炎防控方案(第八版)的通知 | 2020.03.07 | 国家卫生健康委 |
| 医疗机构临床实验室管理办法 | 2004 | 卫医发〔2006〕73号 |
| 病原微生物实验室生物安全管理条例 | 国务院令424号 | |
| 《医疗机构临床检验项目目录(2013年版)》 | / | / |
| CNAS-RL01:2018《实验室认可规则》 | 中国合格评定国家认可委员会 |
提取 DNA 是获取遗传信息的第一步。基因宝采用 Magen 全基因组提取试剂盒能够确保获得纯度高、质量稳定可靠的基因组 DNA 片段。该试剂盒适用于从多种临床样本中(血液、唾液、口腔拭子等)中提取高纯度 DNA,得到的 DNA 可直接用于荧光定量 PCR、生物芯片分析、二代测序等相关实验。
除此之外,该试剂盒基于超顺磁性的磁性粒子纯化技术,可通过自动化核酸提取仪 KingFisher Flex 进行自动化操作,不仅可以减少人为因素感染,还能最大限度去除杂质蛋白及细胞中其它有机化合物,从而满足接下来的扩增等需求。
一般来说,DNA 浓度越高、纯度越高、完整性越好,检测的成功率越高,对应得到的每个位点信息准确度就越高,如果 DNA 的质量较差,测序时出现多位点缺失的风险较大。为了确保后续结果的准确性,基因宝会对刚提取出来 DNA 样品的纯度和浓度进行人工与机器相结合的严格质检。
基因宝采用来自德国 BMG LABTECG 公司的 Omega 全自动多功能酶标仪,对 DNA 进行浓度、纯度检测(注:DNA、蛋白、离子杂质分别在260nm、280nm、230nm处有吸收峰,通过换算从而确定核酸的浓度及纯度),它能够以最小分辨率为1 nm的精度进行紫外/可见光全光谱光吸收扫描(220 nm - 1000 nm),不仅检测速度快,而且准确度和精确度高,有效保障了后续扩增所使用的 DNA 样本符合高标准的要求。
基因宝实验人员使用 0.9% 的琼脂糖凝胶对 DNA 样本进行完整性检测以及纯度的辅助检测,利用凝胶成像系统对 DNA 样本进行观察,要求每个 DNA 样本电泳条带单一、清晰、明亮,无 RNA 污染。此外,基因宝还开发了一套人工智能系统,能够快速准确地识别电泳结果,降低由于人工导致的判读差错。
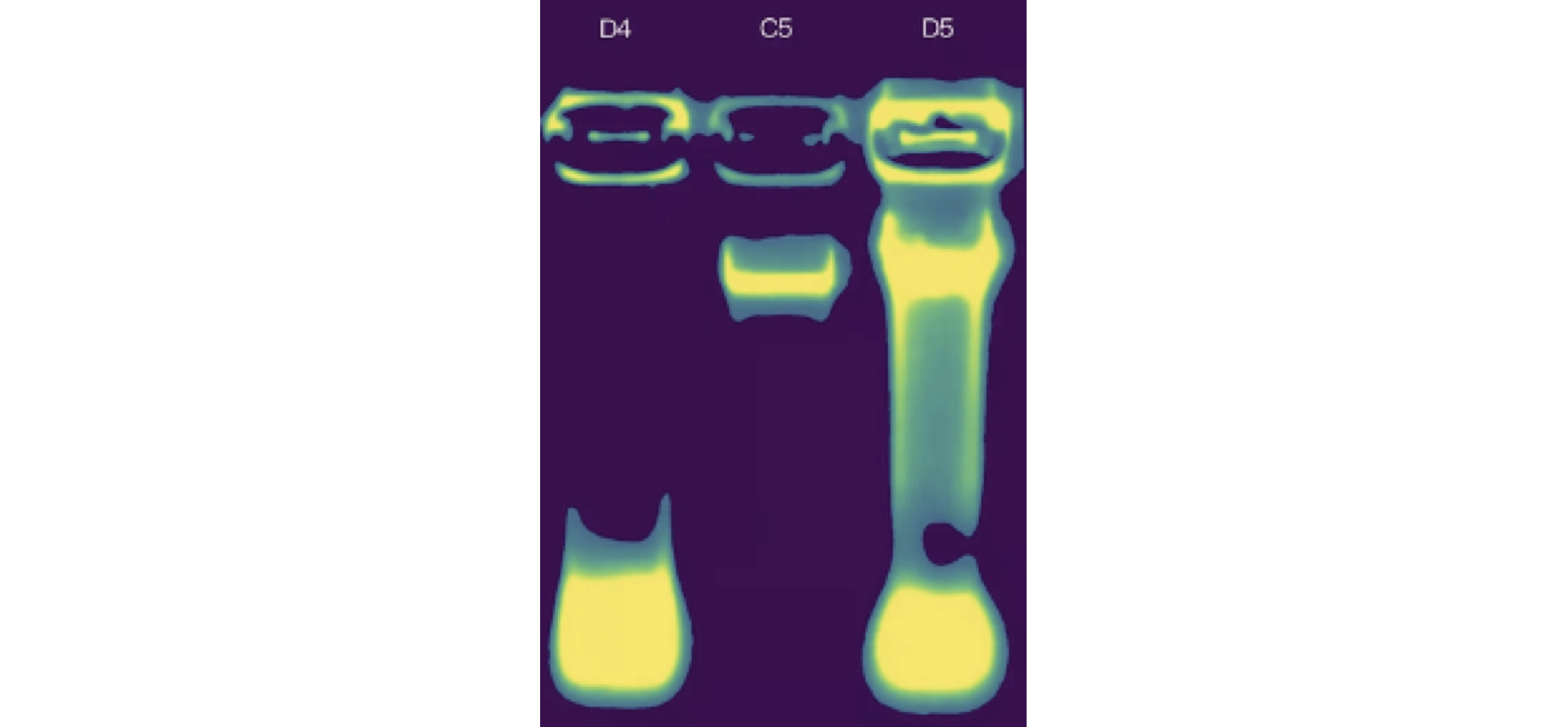
注:若用户样本未能通过质检,基因宝客服人员会及时与用户联系,并为用户提供一次免费的重新采样机会。
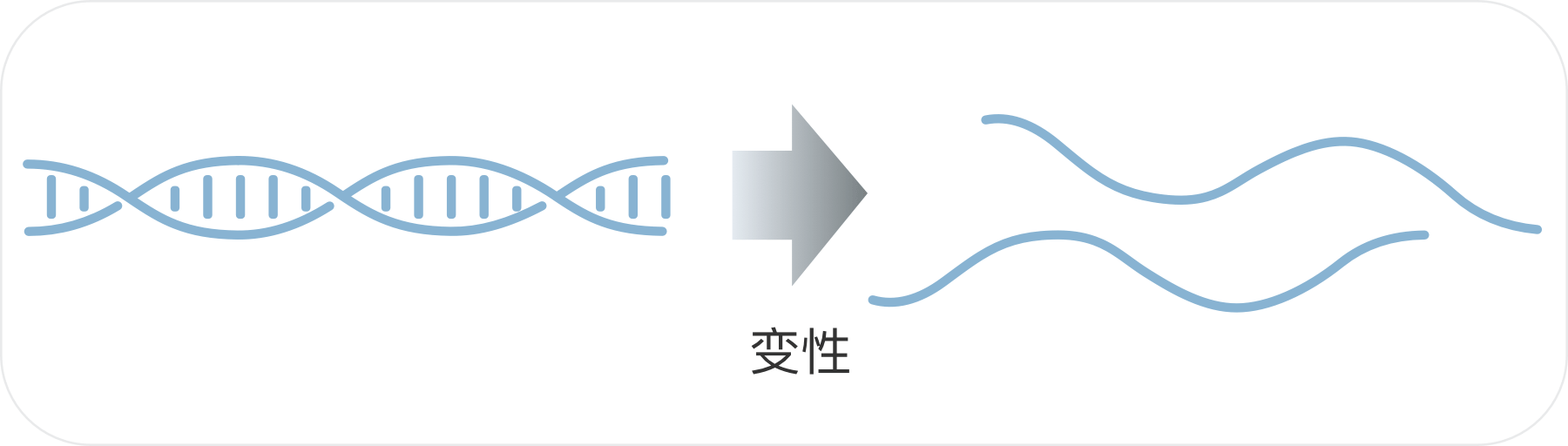
一般通过唾液直接提取到的 DNA 含量较少,很难满足测序的需求。因此在 DNA 质检合格后,会将 DNA 进行“变性”(打开 DNA 的双链结构)以便进行孵育扩增。
基因宝利用恒温扩增方法(尽可能消除 PCR 扩增中的 GC 偏好性),在杂交炉中将 DNA 样本均匀扩增多达一千倍,整个扩增过程会持续 20-24 小时。
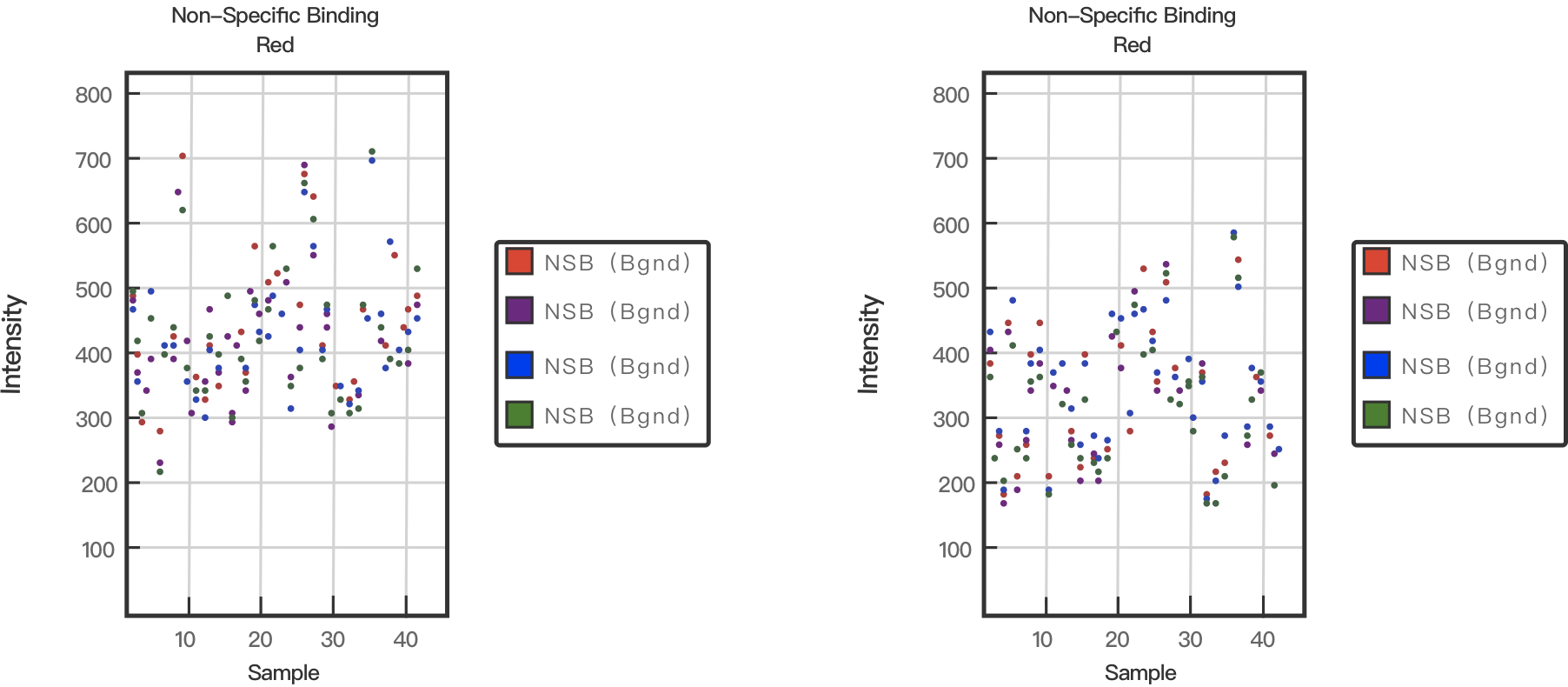
在这个过程中,基因宝会通过引入非特异性对照,检测扩增后的 DNA 与芯片杂交的特异性。非特异性对照的探针是细菌序列的互补序列,在标准杂交条件下不能与人类基因序列杂交。
扩增后的 DNA 会使用特定的生物酶进行酶切,形成 300-600 个碱基对的最佳长度片段,以便与芯片进行杂交。
在 DNA 与芯片进行杂交之前,还需要利用异丙醇来沉淀片段化后的 DNA,并用缓冲液重悬纯化后的 DNA。

由于 DNA 携带的遗传信息数目庞大,为了精确地找到测序所需要的信息,接下来会将重悬后的 DNA 片段与芯片进行杂交,芯片的微珠上连接有 50-mers 长度的特异性捕获探针,这些探针能够与 DNA 互补结合,从而将 DNA “绑定”在芯片上。
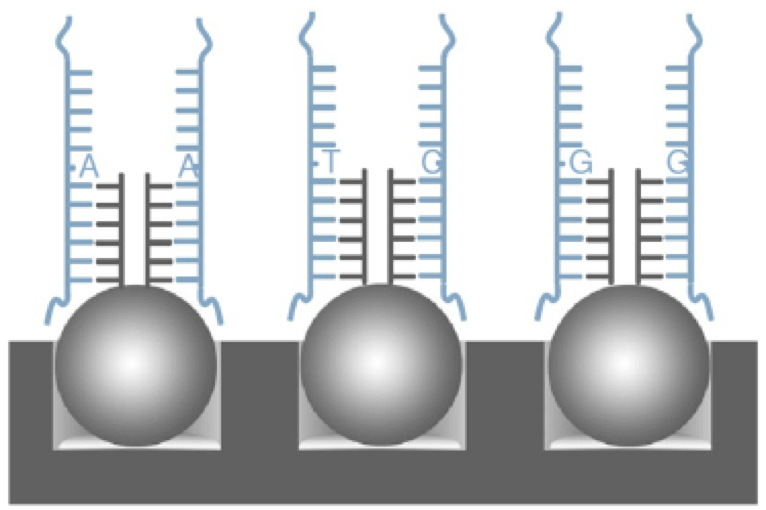
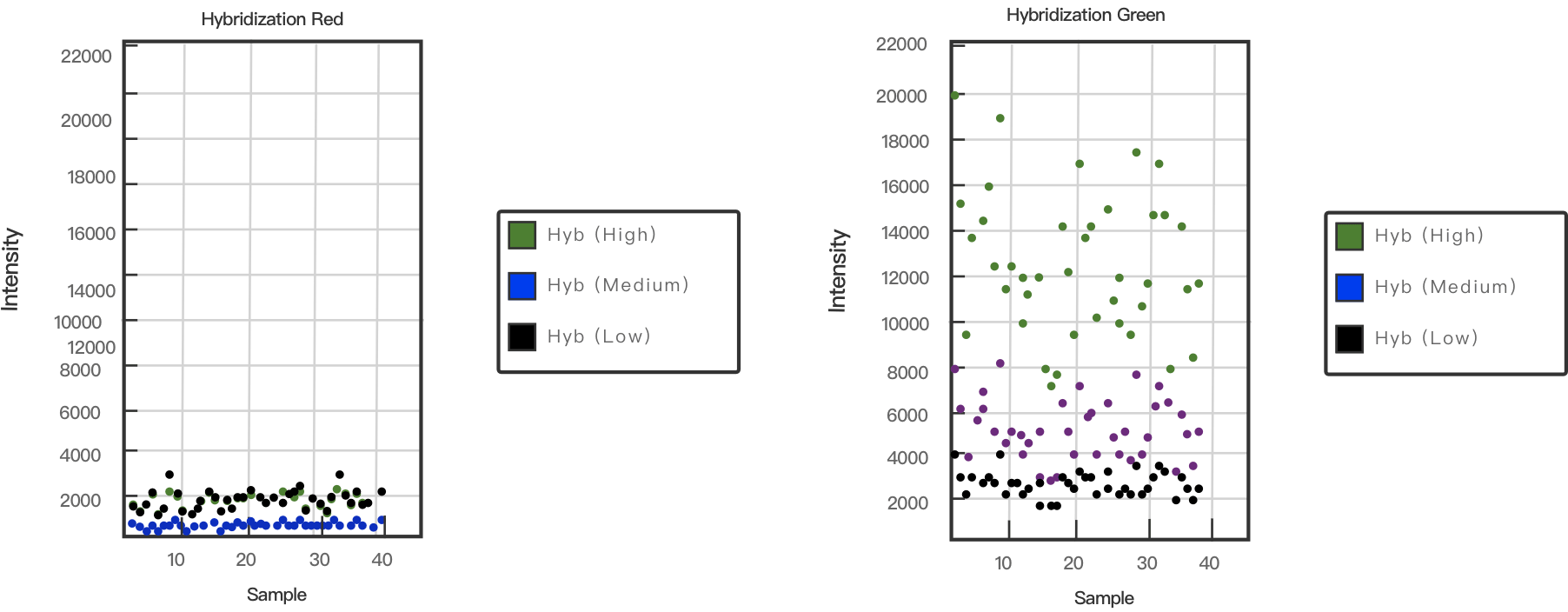
为了确保杂交过程的稳定和高效,在杂交的过程中会引入合成靶标作为对照,这些合成靶标不仅可以与芯片上的探针互补结合,还能作为探针延伸的模板。
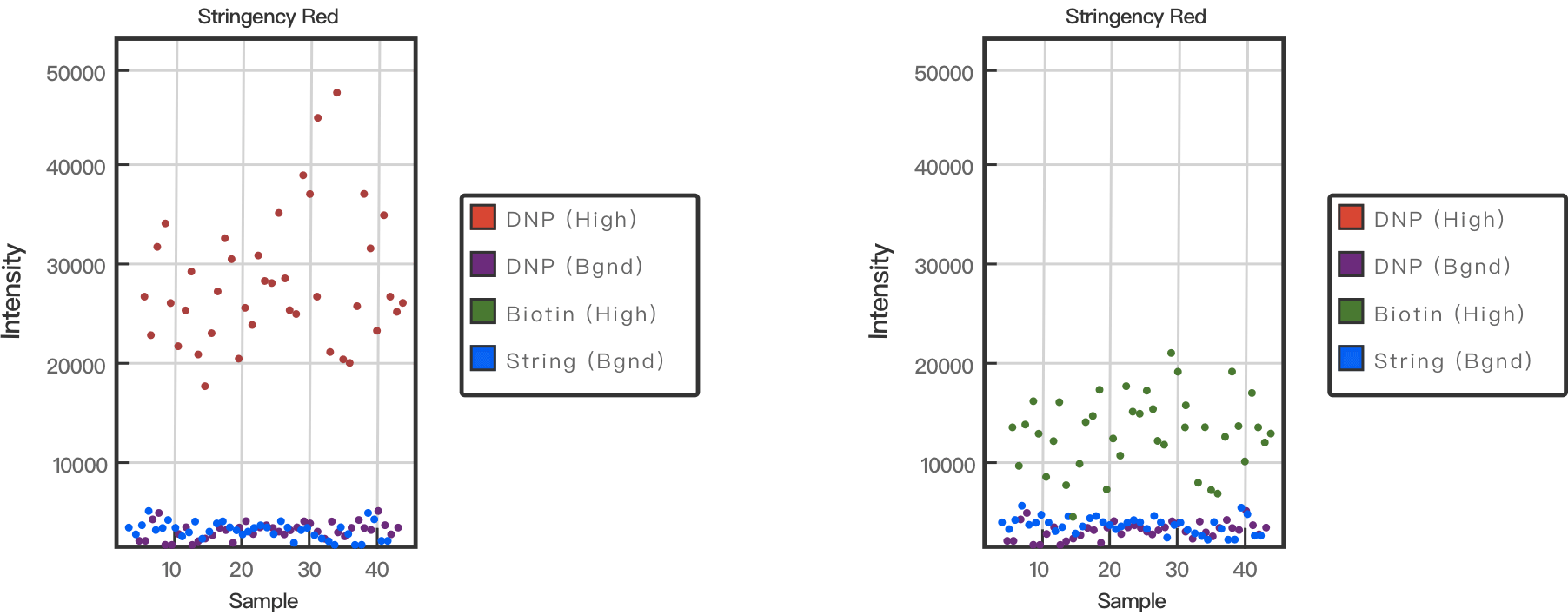
合成靶标会以三种不同浓度存在于杂交缓冲液中,它们用来监测高浓度(5 pM)、中浓度(1 pM)和低浓度(0.2 pM)靶标的反应。杂交对照在绿色通道中以不同强度的信号出现,分别对应于样本检测中的浓度。
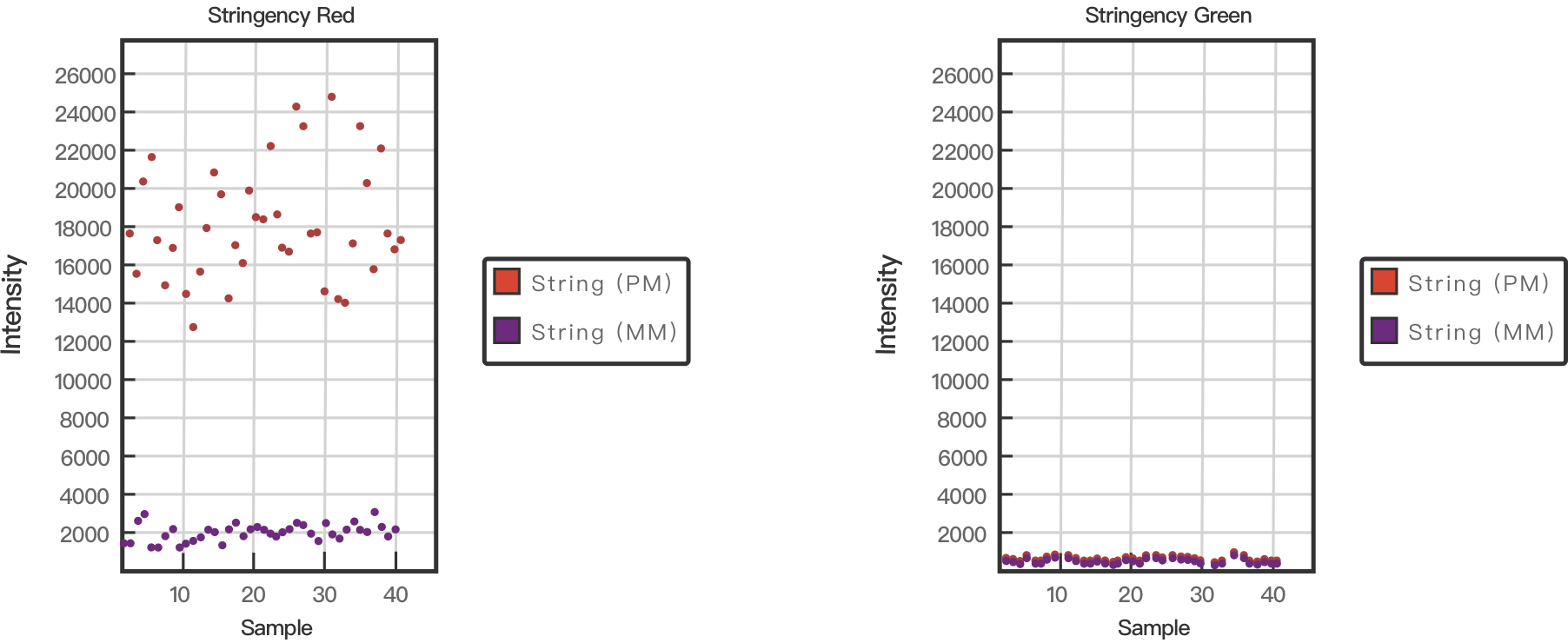
在杂交过程中还会通过错配(MM)和完全匹配(PM)来评估杂交过程的严格程度。
在杂交后会残留一些未被杂交或非特异性杂交的 DNA,如果不清除会影响后续的延伸和染色等过程,需利用缓冲液对芯片进行冲洗,仅保留与探针结合的 DNA。
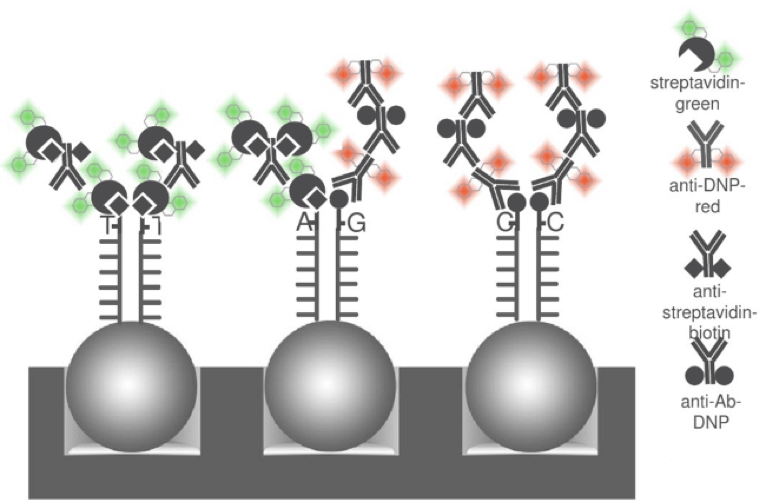
在杂交后,目的基因通过互补配对结合到芯片探针上,为了进一步的区分基因型,在延伸的过程中会给每个探针添加一个标记碱基。单碱基延伸反应采用的是双脱氧链终止法。其中A、T 两种核苷酸用 DNP(二硝基苯)标记,C、G两种碱基用生物素标记。最后纯合子会具有相同的标记,杂合子具有生物素和 DNP 混合的标记。

为了确保碱基延伸的效率,在延伸中会引入对照。对照由充当模板和探针的发夹寡核苷酸组成,在延伸过程中,对照以探针链本身为模板,在 3' 端延伸探针,与 DNA 杂交过程无关。在此过程中,红色通道(A和T)以及绿色通道(C和G)会被实时监测。
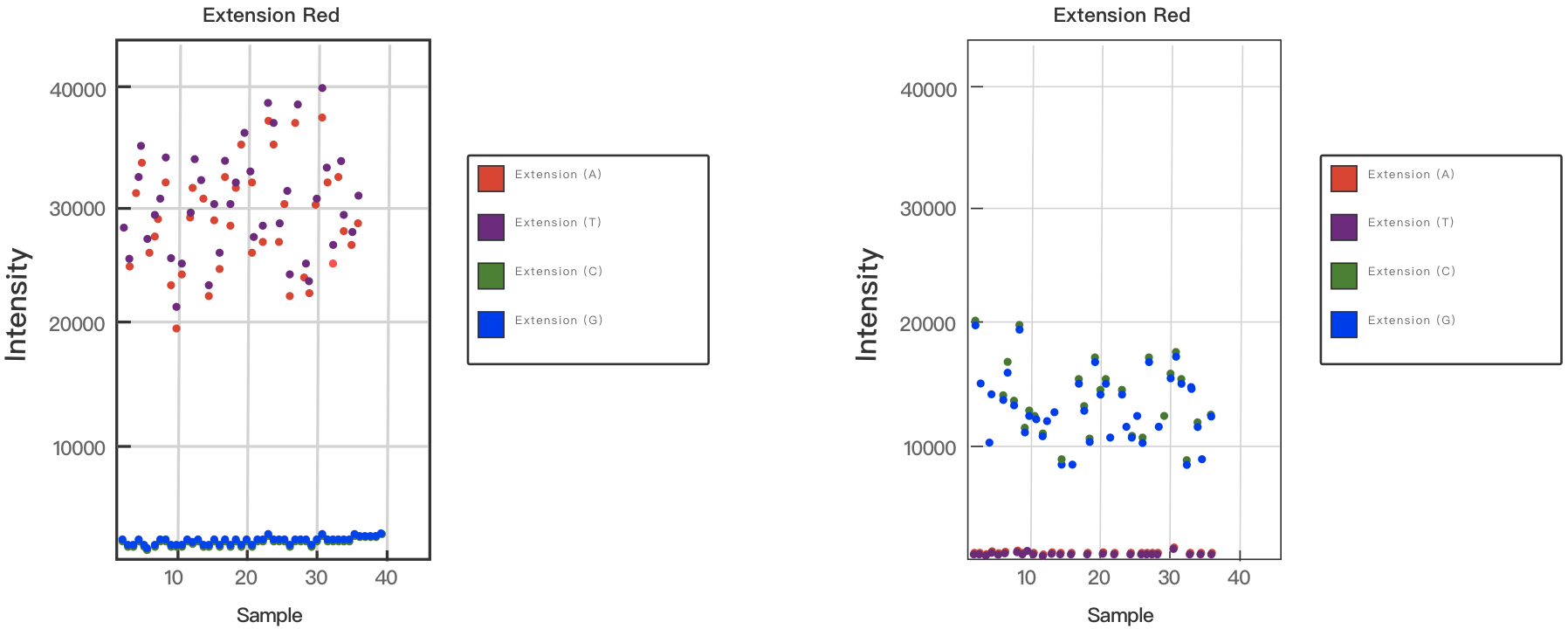
除此之外,为了检测延伸反应后剥离 DNA 模版的效率,还会引入靶标移除对照。如果红色通道中信号较低,说明靶标去除效率较高。
染色的目的是为了芯片探针上的碱基序列变成可被扫描仪识别的不同颜色的荧光信号。在染色过程中,加入绿色荧光标记的链霉亲合素,红色荧光标记的抗 DNP 的抗体。绿色荧光标记的链霉亲合素与生物素特异地结合,让带生物素的 C、G 碱基显出绿色。红色荧光标记的抗 DNP 的抗体与 DNP 结合,让带 DNP 的 A、T 碱基显出红色。
染色结束后,经过清洗,将游离的抗体冲洗掉后,即可进行接下来的扫描步骤。
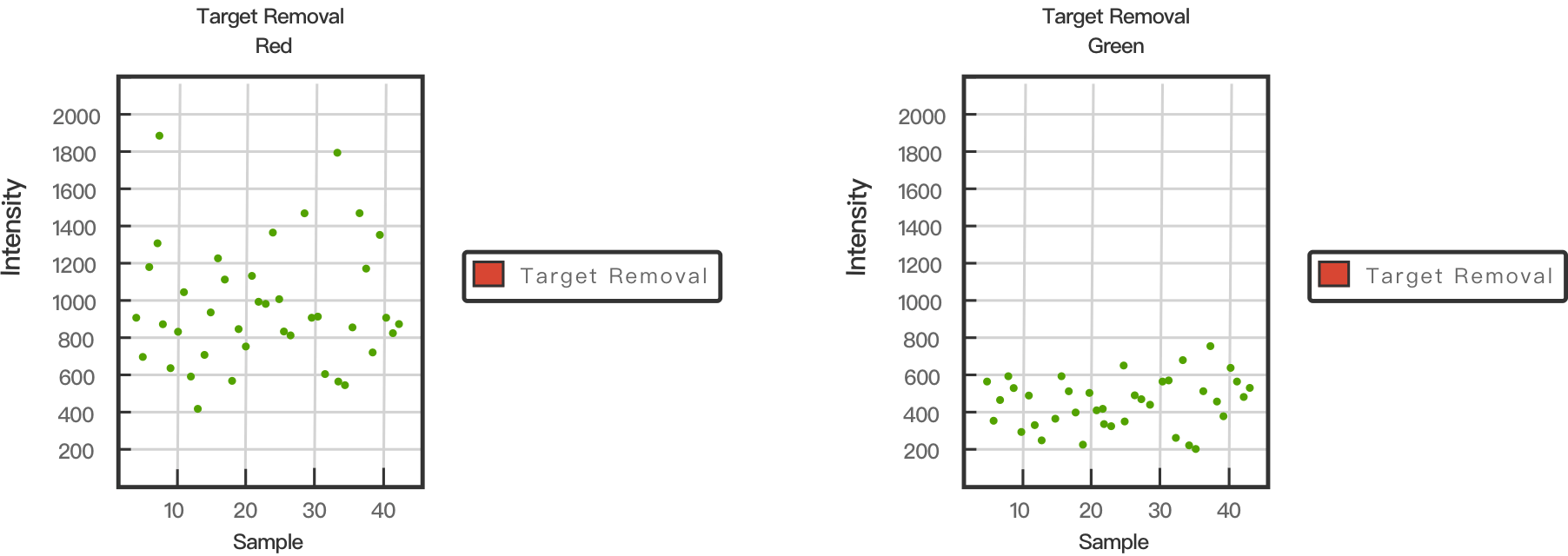
为了确保染色的敏感性和有效性,在染色过程中也会引入对照。对照由高水平或低(本底)水平的二硝基苯基(DNP)或生物素的磁珠组成,并在连续几轮添加绿色荧光链霉亲和素和红色荧光抗 DNP 抗体的过程中被直接标记。染色过程中的红、绿色通道也会被实时监测。
经过洗染后的样本会通过基因宝自研的扫描平台,将不同的荧光信号进行识别和分类,最终使 DNA 中隐藏的 A、G、C、T 四个碱基,转变成可视化的原始数据信息。这些数据信息再通过基因宝自主研发的算法,转化成方便理解的解读报告等内容。

由于目前数据分析尚未有统一的准则,不同公司具有各自不同的生物信息学分析流程以及自己的分析标准,因此结果的准确性可能相差很大。基于此,基因宝公开自己的质控标准以及分析流程,方便大家了解基因宝如何生成基因型数据并确保其高质量,也借此希望推动行业标准的建立。
基因宝的自动化分析包括:下机数据解密、数据完整性校验、数据质控、位点扩增、原始数据导出五个主要过程,具体的流程图如下:
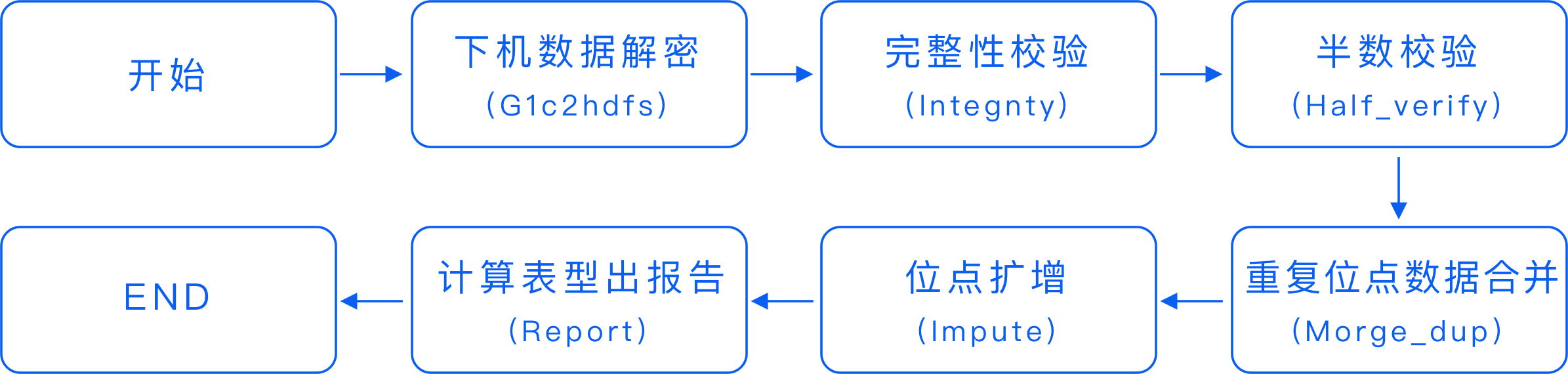
下机之后的数据是二进制文件,在进行后续的质控和分析时则需要根据其特定的规则解密生成相应的 TXT 文件。
由于芯片测序数据量较大,数据在传输过程中可能会存在缺失等问题。因此,基因宝的生信团队会根据下机之后数据在上传到服务器时生成的 md5 文件来校验文件完整性。
MD5 信息摘要算法(MD5 Message-Digest Algorithm),一种被广泛使用的密码散列函数,可以产生出一个 128 位(16字节)的散列值(hash value),用于确保信息传输完整一致。如果测序文件不完整或者被修改,MD5 校验码也会完全不同。
基因数据的质控非常重要,如果数据质量不佳,那么计算的结果准确性和有效性就无法保证。因此,在确定数据完整性后,需要对基因数据进行质控。
基因宝的质控主要包括 Integrity、Half_verify、Merge_dup 这三个步骤:
根据基因数据计算出性别,并确定基因型性别与记录性别是否一致。除此之外,还会对检测出来的基因型数量是否在合格范围内进行判断,不合格的基因数据将会重新实验。
用于校验数据完整性以及检测一个批次内样本合格数量。如果批次内样本合格数超出阈值,那么此批次数据将会重新实验和计算。
对重复的位点数据进行合并。
与全基因组测序相比,高密度芯片测序位点数据量相对较少,即使目前已经覆盖了 74万+ 的位点,但仍可能会存在无法检测到某些 SNP 的可能。
为了避免此类“缺失”数据可能会对检测结果准确性产生影响,通过采用隐马尔科夫模型(Hidden Markov Model, HMM),利用基因型填充的技术精确地预测没有被芯片设计所覆盖的多态性位点的基因型,使得更多的遗传位点应用到关联分析中,从而提高发现新的致病基因的可能性。
在通过整个分析流程后,会为全解锁的用户提供原始数据文件,具体的数据类型如下:
| gxid | chromosome | position | genotype |
| rs1060501922 | 1 | 12061465 | DD |
| rs1060502215 | 1 | 156084831 | GG |
| gx119100001 | 1 | 156105002 | II |
| rs1060502211 | 1 | 156105743 | GG |
| rs1064796677 | 1 | 156105833 | CC |
| rs1064795128 | 1 | 17345431 | DD |
| rs1064794269 | 1 | 17349122 | CC |
| rs1060503764 | 1 | 17349150 | DD |
| rs1487270391 | 1 | 17350489 | II |
| rs1060503759 | 1 | 17350508 | CC |
| gx119100002 | 1 | 17350519 | II |
| rs1060503763 | 1 | 17354343 | AA |
| gx119100003 | 1 | 17355186 | II |
| rs199848267 | 1 | 17380492 | II |
| rs1064793256 | 1 | 237947014 | AA |
在这个文本文档中,其每一行对应一个遗传标记(SNP和Indel)。第一列为 SNP 标识符;第二列和第三列为染色体及碱基对位置(参考GRCh37);第四列为基因型 SNP。